Même pour l’observateur peu attentif, il est apparent que les nouvelles scientifiques ont la fâcheuse tendance de se contredire très souvent. Remarquez que la découverte de résultats scientifiques faux n’a rien d’anormal et est même tout à fait sain, car la force même de la méthode scientifique est de détecter les erreurs. En effet, le fondement de la méthode scientifique, c’est la reproductibilité. Il est donc normal qu’en testant la reproductibilité des résultats, on trouve des discordances de temps à autre avec les observations ou les conclusions de travaux antérieurs.
Le problème c’est la magnitude du phénomène. Le premier à avoir lancé un cri d’alarme est l’épidémiologiste de l’université Stanford, John Ioannidis qui a affirmé en 2005 que la majorité des articles scientifiques sont faux. En effet, selon certaines estimations 75 à 90 % des observations empiriques dans le domaine biomédical sont non reproductibles! Ce qui fait dire à certains que la très grande majorité de la recherche dans ces domaines est un gaspillage d’argent dépassant les 200 milliards de dollars par an! Depuis que cette constatation a été faite, ce questionnement s’est étendu aux domaines de la biologie, de la psychologie, de l’économie et des sciences sociales, qui ont essentiellement les mêmes pratiques de recherche.
Cette prise de conscience est connue sous le nom de la crise de la reproductibilité. Pour celui qui suit le moindrement la littérature scientifique, il s’agit d’un phénomène social majeur. Avec un peu de chance, il aura des impacts positifs durables sur la façon de faire la science.
Le cause du problème ne réside pas dans la méthode scientifique ou dans une culture généralisée de fraude (qui est très rare), mais plutôt dans une culture qui favorise la productivité au détriment de la rigueur. Au cœur du problème, on retrouve le biais de confirmation. Il s’agit d’un phénomène psychologique très simple : quand on cherche quelque chose, on tend à la trouver. Les chercheurs sont particulièrement vulnérables à ce type de biais. Brillants et créatifs, il leur est possible de trouver des interprétations diverses aux données qui vont dans le sens des conclusions qu’ils veulent bien obtenir.
Un exemple classique dans le domaine de l’histoire des sciences est celui des rayons N de physicien français René Blondot. Blondot croyait avoir découvert un nouveau phénomène électromagnétique. Dans son laboratoire, le phénomène était reproductible. Le problème était qu’il ne l’était pas dans le labo d’un collègue américain. Exaspéré de ne pouvoir reproduire ces résultats, il visita le laboratoire de Blondot pour constater que sa machine à rayons N fonctionnait même si elle était débranchée! Blondot s’était fait avoir au biais de confirmation. Des générations de physiciens ont entendu cette histoire ou, alternativement, celle de profs du département qui avait fait le même genre d’erreur.
La première ligne de défense contre le biais de confirmation est la randomisation et le travail en aveugle. En effet, si celui qui prend les mesures ignore la valeur des paramètres testés, il est difficile de pousser les données dans le sens voulu par la conclusion. On peut aussi travailler à double insu. Dans ce cas, le sujet d’étude et l’expérimentateur ne connaissent pas la valeur de paramètres testés. On peut même travailler en triple insu en faisant faire l’analyse des données par quelqu’un qui n’est pas au courant de l’objectif de l’expérience. Malgré la pertinence de cette approche et aussi surprenante que cela puisse paraître, les recherches ne se font pas toujours à double insu, même quand cela est possible.
Au-delà de la technique, il est de plus en plus apparent que le cœur du problème se trouve dans une culture qui valorise la découverte au détriment de la validité des résultats. Produit de cette culture, le biais de publication, où seuls les résultats positifs et les découvertes apparentes sont publiés, de sorte que les résultats négatifs et même les contre-vérifications sont boudés, par les éditeurs scientifiques. Au point, où certaines revues scientifiques refusent carrément d’accepter des articles qui essayent de reproduire des résultats antérieurs! La méthode scientifique en prend pour son rhume.
En plus du biais de publication, il y a le problème dit du «p-hacking». Un terme créé par le psychologue Uri Simonsohn de l’Université de la Pennsylvanie. Il s’agit de la pratique qui consiste à presser les données jusqu’à obtenir un résultat qui dépasse la frontière psychologique du p<0,05, qui est considéré comme le seuil de détection statistique dans bien des domaines. En pratique, cela se traduit par la création d’hypothèse a posteriori, à l’observation simultanée d’un maximum de variables et si ce n’est pas suffisant découper l’échantillon en sous-groupes. Remarquez qu’aucune de ces pratiques n’est en soi fondamentalement incorrecte.
En général, il s’agit d’une limite tout à fait raisonnable quand on ne fait qu’un seul test. Le problème est que lorsque l’on fait plusieurs tests, la probabilité d’obtenir un résultat positif par hasard augmente exponentiellement. Il faut donc augmenter significativement le seuil de détection pour faire une découverte (correction de Bonferonni)
C’est pour cette raison que les physiciens des particules ne considèrent pas qu’une découverte est valide tant qu’elle n’a pas atteint le seuil de 5 écarts types, ce qui correspond à un p de 1/3,5 millions, car ils font une quantité énorme de mesure simultanément. Je me souviens d’avoir lu dans une publication du CERN que cette valeur a été choisie après que l’expérience ait montré que les signaux à quatre écarts types (1/31 574) étaient faux une fois sur deux. De même, en astrophysique, il est relativement connu que les mesures avec un rapport signal à bruit de 5 sont biaisées, pour cette même raison.
Un exemple de cette pratique est le papier de Carman et al. 2013 portant sur la toxicité des OGMs. Les chercheurs ont examiné 40 indicateurs physiologiques à la recherche d’un effet toxique. Et en plus, l’inflammation de l’estomac a été divisée en 4 niveaux et par sexe pour faire augmenter la signifiance statistique du signal.
En plus des efforts de manipulation des données de la part des chercheurs, il y a aussi une mauvaise interprétation de la signifiance statistique. En effet, il faut savoir que le choix d’un seuil de 5 % est purement arbitraire. Quand il a été proposé dans les années 20, par le statisticien britannique Ronald Fisher, il n’avait pas pour but d’être un test définitif pour définir une découverte. C’est plutôt un indicateur qu’il y avait peut-être là quelque chose d’intéressant à explorer. À cette époque, les statisticiens polonais Jerzy Neyman et britannique Egon Pearson développaient une approche alternative basée sur la puissance statistique et les faux positifs et négatifs, qui n’utilisait pas la valeur p. Les deux approches étant incompatibles, il s’en suivit une guerre intellectuelle entre les deux équipes.
Las de cette situation, d’autres chercheurs ont produit des manuels de statistiques pratiques qui combinaient les deux méthodes. Cela transforma la signification de la valeur p en une indication de sujet d’intérêt en preuve de découverte formelle. Ce qui est fondamentalement faux.
En effet, pour être utilisée correctement, la valeur p doit être combinée avec une hypothèse initiale de la probabilité de la réalité d’un phénomène. Cette approche, dite bayésienne, tient compte de l’information préexistante. Ainsi, les hypothèses les moins plausibles – télépathie, télékinésie, extra-terrestres, homéopathie – ont plus de chances d’être fausses que des hypothèses plus banales pour la même valeur de p.
Par exemple, si au départ les deux hypothèses sont aussi valides (l’effet existe ou n’existe pas), car on n’a pas d’information a priori, un p de 0,05 correspond plutôt à un taux d’erreur entre un 1/3 et 1/5 et p=0,01 entre 1/12 et 1/20! Alors, si vous allez à la pêche en examinant plusieurs variables et en faisant un peu de p-hacking, vous êtes quasiment certain de faire une découverte, mais cette dernière sera très probablement fausse!
")
Cette sur-interprétation des données a pour conséquence la production d’une quantité hallucinante d’études scientifiques de faible valeur. Par exemple, des dizaines d’études scientifiques montrent que presque tous les aliments causent et préviennent simultanément le cancer. Ce qui permet aux charlatans de tout acabit de proposer un menu anticancer prouvé scientifiquement en faisant une lecture sélective de la littérature.
")
Les champs électromagnétiques vous préoccupent. Pas de problème, il y a des centaines d’articles qui montrent que cela provoque le cancer ou le prévient. Il suffit de choisir dans la pile. Au passant, je vous invite à comparer ce dernier graphique à cette étude classique sur la psychokinésie. Ne chercher pas la différence, il n’y en a pas! Dans le deux cas cependant, les résultats convergent vers ce que la physique prédit: zéro effet.
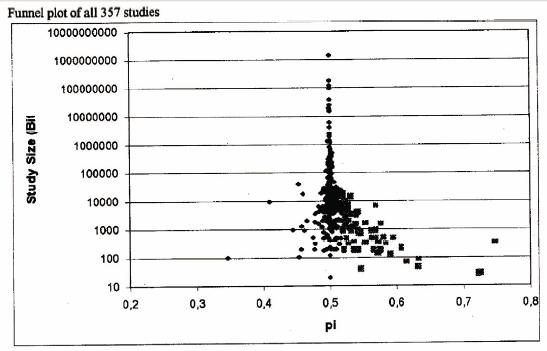
Une façon simple de corriger ce problème serait d’augmenter le seuil de détection statistique à un niveau plus réaliste. Ainsi, on pourrait utiliser p=0,005 et p=0,001 comme seuils d’un effet significatif et très significatif. Correspondant, à des taux d’erreur de 1/20 à 1/50 et 1/100 à 1/200 respectivement. Le prix à payer pour atteindre ce niveau de certitude est d’augmenter la taille des échantillons par un facteur 2, ce qui est plus coûteux, mais fait réduire le nombre de faux positifs par un facteur 5.
Une autre façon de limiter le problème est de présenter les résultats sous une forme graphique parlante, ce qui est rarement le cas dans bien des domaines où l’on préfère utiliser des tables. Pourtant, le graphique à lui seul contient souvent suffisamment d’information pour que la signifiance du phénomène puisse être évaluée d’un coup d’œil pour peu qu’il soit bien construit.
Il est très possible de faire de la recherche sans produire des montagnes de faux résultats positifs. Ainsi, dans le domaine de la physique, des mathématiques et du génie, la très grande majorité des résultats sont valides. Il n’y a pas de statistiques publiées sur la validité des découvertes dans ces domaines, mais en examinant simplement la banque de données de l’Extrasolar Planets Encyclopedia, on note que seulement 197 des 1924 planètes dans la banque de données sont non confirmées, controversées ou ont été rétractées, soit 10,2 %. Il faut dire que les physiciens sont en général plus rigoureux dans leur analyse statistique, mais aussi plus craintifs face à l’annonce d’une fausse découverte.
C’est probablement là où se trouve le nœud du problème. En effet, le contre-argument qui m’a été servi à chaque fois que j’ai dénoncé cette situation était que d’augmenter la rigueur des analyses allait réduire le nombre de découvertes, même si la majorité d’entre elles sont présentement fausses. Tant que cette culture ne changera pas, on ne peut pas espérer de progrès et les sciences continueront à nourrir les pseudosciences.
Ajout du 28 mai
Un petit commentaire d’un astrophysicien québécois chasseur d’exoplanète, David Lafrenière, qui illustre bien la différence culturelle qu’il peut y avoir au sujet de la notion de certitude.
«En 2008, on a publié une découverte de planète après une seule époque, mais avec un spectre, où l’on estimait que la probabilité que l’objet soit réellement une planète liée était de 99,8 %, ce n’était donc pas une certitude (on n’a pas attendu la certitude pour publier), mais c’était bien statistiquement significatif.»
Lectures suggérées:
Dossier de Nature sur la crise de la reproductibilité
De la méthode scientifique, un de mes vieux billets sur Science on Blogue!
En tant qu’enseignant, j’ai toujours une question qui me turlupine.
J’évalue (donc je mesure) des élèves avec divers instruments de mesure: Examens, contrôles, laboratoires. Parmi les résultats, il faut éviter les vrais-faux, à tout prix (ceux qui ne réussissent pas et qui auraient dû réussir). Ce sont les faux-vrais qui me questionnent (ceux qui réussissent et qui n’aurait pas dû réussir).
Pour diminuer, l’erreur sur la mesure, augmenter le nombre d’évaluations peut s’avérer une solution (mais cela reste à démontrer).
Pour diminuer, encore plus, la marge d’erreur, une double mesure est effectuée sur une partie de l’évaluation. C’est l’examen du ministère. Le ministère considère que leur instrument de mesure a une marge d’erreur de 0,5 à 2 % selon les années.
Il ne faut pas oublier qu’un faux-vrai peut devenir un vrai dans l’avenir et selon les circonstances (et l’inverse aussi est possible).
Par expérience, on a tendance à laisser jouer la non-linéarité du résultat de façon à reprendre une mesure l’année suivante.
Je signale des coquilles :
« les recherches ne se font pas toujours à double insu, mais quand cela est possible. »
« les événements 4 à quatre écarts types »
Et une question :
« Ainsi, dans le domaine de la physique, des mathématiques et du génie »
Le génie, qu’est-ce ?
Merci pour cet article intéressant !
Merci! Je corrige.
Le génie, c’est l’ingénierie.
i-La reproductivité est probablement plus difficile à vérifier au fur et à mesure que l’objet de recherche est petit, pcq plus changeant.
ii-Question : l’approche bayésienne prend-elle pour modèle l’algorithme c’est-à-dire qui se réfère aux résultats passés, une sorte de courbe d’apprentissage ?
iii-Au CERN, il me semble que c’est à partir du 5 écarts type qu’on a décrété l’existence du boson de Higgs.
En fait, c’est plus difficile plus l’effet est faible et moins les variables sont contrôlées. Ce qui est souvent le cas des études épidémiologiques.
L’approche bayésienne permet de combiner de l’information a priori avec des nouvelles information de la façon la plus optimale possible. C’est effectivement un sorte d’apprentissage. Ce qui a fait dire à la philosophe des sciences Deborah Mayo que c’était le cœur de la méthode scientifique.
Effectivement, le standard du CERN c’est 5 écarts type.
Intéressant billet, Ivan, mais je renâcle sur plusieurs points quand même. C’est difficile de lancer le débat dans si peu d’espace, mais la « méthode scientifique » n’existe pas, ou n’est qu’une construction a posteriori. Si elle existait, elle serait enseignée… (je sais tout n’est pas tout blanc ou noir, mais quand même).
Utiliser les méthodes bayésiennes c’est sûrement très bien techniquement, mais il y a plein de résultats qui sont « obtenus » (lire: construits) dans la formulation même des paragraphes et leurs enchaînements dans un article. Il faut parfois 5 lectures pour s’apercevoir d’un problème. La technique aide peu dans ces cas-là, autrement plus difficiles à détecter.
Et quid de la reproductibilité des phénomènes variables en astrophysique? Nombreux sont ceux qui sont virtuellement impossibles à reproduire, malgré une bonne volonté. L’astrophysique serait-elle une fausse science comme certains osent l’avancer?
Bref, les pourcentages et les techniques c’est bien. Ce qui me semble tuer la recherche (et donc financer les pseudo-sciences, je suis parfaitement d’accord sur ce point) c’est un truc simple, mais difficile à changer: la compétition. Et en particulier la compétition des financements, farce qui a été inventée de toutes pièces et servie aux scientifiques crédules.
Au plaisir de débattre encore!
Bonjour Cédric,
Les méthodes bayésiennes, c’est juste une façon de formaliser mathématiquement ses hypothèses. Si les hypothèses de départ sont fausses cela ne changera rien au résultat.
Les phénomènes transitoires ou très rares posent toujours un problème à la science. Je pense au cas de certains noyaux atomiques qui n’ont été produits qu’à une poignée d’exemplaires. Un peut aussi penser à la mesure des neutrinos de 1987 A. Dans ce cas, il est assez clair que la reproductibilité est douteuse. D’un autre coté, pour cette raison, il reste toujours un doute sur la mesure.
À mon avis, le problème réside dans la façon dont on mesure la productivité scientifique. Compter les articles et les citations, c’est facile. Cependant, cela ne veut pas dire grand chose si la majorité des citations n’est que par politesse et si le papier est faux. Au final, c’est un peu comme le PIB.
J’ai un collègue de TÉLUQ qui a produit un travail intéressant à ce sujet:
https://www.researchgate.net/profile/Peter_Turney/publication/260072813_Measuring_academic_influence_Not_all_citations_are_equal/links/0c96052f4d1aa0b6b8000000.pdf
Bonjour,
J’ai présenté votre billet à un ami qui m’a répondu : « Il devrait relire Kant avant de publier un article aussi douteux que ce qu’il dénonce… ».
N’ayant pas lu Kant, je lui ai demandé de m’expliquer, ce qu’il a refusé de faire en disant que je pouvais très bien me débrouiller par moi-même.
Malheureusement, je n’ai pas le temps d’éplucher tous les écrits de Kant pour vérifier ses propos, donc je ne saisi pas de quoi il parle. Pourriez-vous m’éclairer ?
Bonjour,
J’avais lu cette discussion sur Facebook. Je suis aussi dubitatif que vous. D’une part, les idées exposées dans ce texte sont postérieures à Kant, alors il faut faire attention ses écrits pour les interpréter. Peut-être fait-il référence à Critique de la raison pure et à la théorie de la connaissance. Encore là, je ne vois pas où est sont point.
Au moins, cela fait changement de se faire citer Kuhn, qui est toujours la référence de base des post-modernistes.
Où sont les philosophes quand on a besoin d’eux?
Réponse d’un copain philosophe:
Bonjour,
Sans vouloir être baveux, voici probablement un individu qui a mal « digéré » son bacc en philo (la première intervention, pas la dernière – quoiqu’elle me semble un brin condescendante). Premièrement, l’objectif de la CRP n’a jamais été de critiquer la méthode scientifique. Au contraire, les travaux de Newton sont l’une des principales inspirations de Kant. En fait, son objectif était simplement de (re)fonder la métaphysique.
Cela dit, à mon avis, cette personne voulait probablement insister sur la distinction entre la connaissance de la « chose en soi » (noumène) et la chose telle qu’elle nous apparait (phénomène). Pour Kant, on ne peut qu’avoir une connaissance phémonénale, c’est-à-dire médiatisée – des objets. Alors, quiconque prétend avec une connaissance absolue (le terme est important) – et donc immédiate – grâce à la science parle à travers son chapeau selon Kant.
De toute façon, je doute qu’une pareille attitude soit compatible avec le principe de réfutabilité qui, vous me corrigerez si je me trompe, est universellement admis en science.
En bref, il ne faut pas confondre métaphysique et science.
Effectivement, je pense que votre interprétation est la bonne.
J’abonde dans le sens de A Cloutier.
Kant a dit de David Hume qu’il l’avait sorti de son sommeil dogmatique. J’ai tendance à penser que la pensée de Kant sur le noumème et le phénomène est une vue de l’esprit.
Ultimement je suis convaincu que tout est impermanent, décomposable et transitoire. Relativement, c’est une autre paire de manches et nous vivons dans un monde relatif. Entre l’infiniment grand de l’astrophysique et l’infiniment petit des particules subatomiques, il y a un monde bien réel.
J’aurais dû écrire : « j’ai tendance à croire que la pensée de… ».
Merci pour vos réponses !
Je pense de toute façon que mon ami était plus dans l’optique de « me donner une leçon » que dans une réelle démarche de réflexion, mais au moins je repartirai un peu moins bête 😉
Bravo et merci pour ce billet très instructif!
La statistique est un outil puissant qu’il faut bien maîtriser pour ne pas faire dire n’importe quoi aux chiffres.
Voici une histoire promue par les adversaires de la vaccination qui ressort à l’occasion comme une nouvelle… celle du lien entre la narcolepsie et certains vaccins.
Par exemple l’histoire ressort en septembre 2012.
Source: http://www.lemonde.fr/sante/article/2012/09/20/le-vaccin-pandemrix-soupconne-d-entrainer-des-risques-de-narcolepsie_1763335_1651302.html
C’est un peu de la désinformation comme l’histoire du lien entre l’autisme et les vaccins. On trouve de tout sur internet.
En effet, on constate une « corrélation statistique » entre un accroissement des cas de narcolepsies avec le vaccin « Pandemrix » utilisé en Europe contre le H1N1 qui contient un adjuvant appelé ASO3 (une substance utilisée pour amplifier la réaction immunitaire).
Source: http://www.cdc.gov/vaccinesafety/Concerns/h1n1_narcolepsy_pandemrix.html
Or tout scientifique sait que corrélation n’est pas explication (causalité) et il ne faut pas sauter aux conclusions trop vite.
En effet, une étude de la Stanford School of Medecine montre que le lien n’est pas entre le vaccin et la narcolepsie mais plutôt entre la grippe et la narcolepsie. Mais de cette étude les « anti-vaccins » n’en parlent pas!
Source: http://med.stanford.edu/ism/2011/august/narcolepsy.html
Donc attention de jeter le bébé avec l’eau du bain…
Maintenant, admettons quand même qu’il y ait un « vrai » risque accru de narcolepsie à cause spécifiquement de ce vaccin, il faut alors balancer le bénéfice et le risque encouru. Combien de vies sauvées et de complications évitées par l’usage du vaccin.
Je vais essayer de l’estimer…
Le fabricant du vaccin, GlaxoSmithKline, rapporte que sur 31 millions de doses de Pandemrix, 162 cas de narcolepsie ont été observés.
D’autres sources parlent de quelques centaines. En passant, la narcolepsie n’est pas mortelle.
Source: http://www.theglobeandmail.com/life/health-and-fitness/health/conditions/who-probing-reported-link-between-h1n1-vaccine-narcolepsy/article623507/
On estime à 0,4 pour 1000 le taux de mortalité de H1N1.
Source: http://fr.wikipedia.org/wiki/Grippe_A_(H1N1)_de_2009-2010_par_pays
Donc 31 millions de doses auraient potentiellement sauvé un peu plus de 12 000 vies.
Donc on met dans la balance quelques dizaines voir quelques centaines cas de narcolepsies non mortelles versus 12 000 vies…
Il n’y a pas de médicaments ni de vaccins sans effets secondaires, sinon cela veut dire qu’ils sont sans effet donc inefficaces.
D’ailleurs on peut trouver ci-dessous une liste d’effets secondaires du Pandemrix
Source : http://en.wikipedia.org/wiki/Pandemrix
Le problème, ce peut être l’insuffisance de tests avant l’introduction d’un nouveau médicament ou vaccin et l’avidité des compagnies pharmaceutiques. C’est la raison des essais cliniques. En fait, on fait pour le mieux, car c’est simplement impossible de couvrir tous les cas et toutes les combinaisons d’effets possibles pour toutes les populations possibles.
Mais il y a aussi l’urgence d’agir… Dans le cas de H1N1, on a réduit les doses de vaccins pour augmenter celle des adjuvants afin de pouvoir traiter un plus grand nombre de personnes. Cela apparaît un compromis raisonnable surtout qu’à l’époque on ne pouvait pas savoir si H1N1 ne constituait pas un grave menace.
Même, l’eau pure est dangereuse…
Source: http://www.sciencepresse.qc.ca/actualite/2011/08/01/boire-beaucoup-deau-dangereux
Cela dit, j’espère que personne ne veut retourner dans le passé, avant les progrès de l’hygiène et de la vaccination, où des millions de personnes mourraient de la peste et autres maladies contagieuses. La mortalité infantile était effroyable! Au 18e siècle un enfant sur quatre mourrait avant l’âge d’un an (désolé pas de source…).
Scientifiquement vôtre!
Merci de ce commentaire intéressant. Si ma mémoire est bonne, il a été établit que la cause de la narcolepsie était la ressemblance entre une protéine de surface du virus et une des cellule du cerveau des malades. Ce genre d’accident est donc inévitable.
En parlant de corrélation accidentelles. Le site Spurious Correlation est une source intarissable.
Et pour faire pompeux, parce que l’on est des méchants intellos méprisant le menu peuple : Cum hoc ergo propter hoc.
@Yvan Dutil
Ou la réciproque « Cum hoc sed non propter hoc. »…
Merci pour le lien vers « Spurious Correlation », c’est un site vraiment très drôle… à se rouler par terre.
Voici un très bel exemple du danger de tester de multiples hypothèses dans la même analyse. Je me suis dit que cela allait plaire à notre astrophysicien car il s’agit d’astrologie!
Il s’agit de l’étude datant de 2006 du statisticien canadien Peter Austin (Institute for Clinical Evaluative Sciences, Toronto.) qui a calculé des corrélations entre les causes de décès et le signe astrologique de millions de personnes.
Un article dans « The Economist », 22 février 2007: http://www.economist.com/node/8733754
Quelques-unes de ses conclusions:
Les Béliers sont plus à risque d’infections intestinales. Les signes du Taureau de se fracturer le col du fémur. Les Gémeaux de devenir alcooliques. Les Poissons de mourir d’une crise cardiaque…
Plus de détails sur ces prédictions: http://www.canada.com/story_print.html?id=c42e4b5b-ca0b-4e09-b634-1ebfa4cd2a3d
Évidemment, ces conclusions basées sur pas moins de 24 hypothèses simultanées (2 par signes astrologiques) s’effondrent comme un château de cartes quand on augmente le seuil de détection comme suggéré dans le billet de M. Dutil.
Plus de détails sur la méthodologie: http://www.sas.com/offices/NA/canada/downloads/presentations/Toronto_datamining2008/Astrology.pdf
Super! Ce qui est intéressant, c’est le risque relatif de 1,1 à 1,8, qui est typique de ce que l’on observe dans études qui détectent des risques là où ne de devrait pas y en avoir.
Un autre papier similaire vient de sortir:
Birth Month Affects Lifetime Disease Risk: A Phenome-Wide Method
Les auteurs trouvent 55 maladies corrélées avec le mois de naissance sur un ensemble de 1688. Soit 3,2 % des maladies.
Les auteurs utilisent la correction de Benjamini-Hochberg au lieu de la correction de Bonferonni. Cela favoris eun peu les faux positifs.
Correlation n’est pas raison!
Je m’excuse d’accaparer l’espace de votre blogue… Mais le sujet me passionne et j’aimerais me livrer à un petit exercice pédagogique pour les lecteurs de bonne volonté qui aimeraient mieux comprendre sans avoir beaucoup étudié les statistiques. Je partirai donc d’une petite expérience avec des dés à jouer.
En général, quand on fait une découverte avec les statistiques, il faut s’assurer qu’elle n’est pas due au hasard. C’est à cela que servent les tests statistiques et le fameux facteur p (p-value).
Les tests statistiques servent à répondre à la question « Dans quelle mesure le hasard pourrait expliquer à lui tout seul la relation observée? ». De même, on dira que le facteur p représente la probabilité que le hasard puisse expliquer à lui seul la relation observée.
Maintenant, livrons nous à une petite expérience avec des dés…
Prenons deux dés à jouer, disons un dé dans chaque main pour pouvoir facilement distinguer les résultats. Nous allons lancer ces dés une dizaine de fois et noter les résultats (1,2,3,4,5 ou 6).
Or bien que nous sachions que les deux séries de lancers de dés soient indépendants, rien ne nous interdit de calculer la corrélation entre les deux séries de lancers. Estimer la corrélation entre deux variables aléatoires, c’est estimer l’intensité de la liaison qui peut exister entre ces variables à l’aide d’une droite (dépendance linéaire entre les deux variables). Notez qu’il existe des dépendances non-linéaires, et que le signe de la corrélation peut être négatif, mais nous n’entrerons pas dans ces considérations.
La corrélation (sans le signe, ou en valeur absolue) est un nombre entre 0 (variables indépendantes) et 1 (variables linéairement dépendantes). Une corrélation de 0,95 peut être considérée très faible si l’on vérifie une loi physique, mais peut être considérée comme élevée dans les sciences sociales.
En fait, même si nous savons que les deux séries d’événements sont indépendants, le hasard fait que l’on obtienne la plupart du temps des corrélations faibles (autour de 0, bien que jamais rigoureusement 0) mais aussi parfois de fortes corrélations.
Par exemple, si on se fixe une corrélation minimale de 0.6 et en s’armant de patience, on finira par générer au hasard deux séries de lancers qui auront une corrélation supérieure.
Au lieu de lancer « physiquement » des dés, j’ai fait une petite simulation informatique. On voit qu’au bout de 35 expériences, on obtient une corrélation de près de 0.7
Nombre d’expériences: 35
Corrélation: 0.692131495247
dé 1: [3 4 3 4 1 3 1 4 4 4]
dé 2: [6 6 3 5 3 2 2 6 6 4]
Le code de la simulation en langage Python:
import numpy as np
nbre_experiences, correlation = 0, 0.0
while correlation < 0.6:
nbre_experiences += 1
lancer_de_1 = np.random.randint(1,7, size=10)
lancer_de_2 = np.random.randint(1,7, size=10)
correlation = np.corrcoef(lancer_de_1,lancer_de_2)[0,1]
print "Nombre d'expériences: ", nbre_experiences
print 'Corrélation: ', correlation
print "dé 1: ", lancer_de_1
print "dé 2: ",lancer_de_2
Premièrement, tous les commentaires pertinents sont les bienvenus. Dans les blogues de sciences, les fils de discussions sont généralement plus intéressants que les billets.
En plus, du code en Python, c’est tellement geek.
Oups!
Le code Python doit être indenté correctement car Python est particulièrement capricieux (les points devant les instructions représentent des espaces)
import numpy as np
nbre_experiences, correlation = 0, 0.0
while correlation < 0.6:
….nbre_experiences += 1
….lancer_de_1 = np.random.randint(1,7, size=10)
….lancer_de_2 = np.random.randint(1,7, size=10)
….correlation = np.corrcoef(lancer_de_1,lancer_de_2)[0,1]
print "Nombre d'expériences: ", nbre_experiences
print 'Corrélation: ', correlation
print "dé 1: ", lancer_de_1
print "dé 2: ",lancer_de_2
Excellent sujet expliquant bien la difficulté pour un passionné de science à évaluer la pertinence et la valeur d’un article pour en parler et en nuancer la teneur de façon éclairée.
Bonjour,
Je reviens au sujet du débat avec mon ami, car j’en sais un peu plus. Voilà ce qu’il m’a répondu :
« Ce qu’il oublie dans son article, c’est la révolution kantienne […]. Or c’est le fondement même de la démarche scientifique encore à ce jour.
Un objet quelqu’il soit n’apporte aucune connaissance, c’est l’esprit humain qui l’a produit.
Par extension, dans l’esprit humain on trouve des biais de raisonnement. Et ces biais sont également à l’origine de découvertes car justement on a besoin quand on fait de la recherche, on attend des résultats même si ce ne sont pas ceux auxquels on s’attendait.
Bon nombre de connaissances a été du soit à ces biais soit au hasard. Alors la démarche scientifique, je pense qu’il faut aussi savoir la relativiser.
D’ailleurs les biais de raisonnement n’ont jamais empêché les connaissances. Par ailleurs parfois, quand un article de sciences sociales te dit que telle méthode ne marche pas alors que sur tes patients tu vois que si, qu’est-ce que tu peux te dire ? Moi je me dis que la démarche scientifique biaise complètement également les résultats en ne tenant pas compte des différences individuelles par volonté d’universalité. L’article pour moi est mal orienté, c’est la démarche qui est obsolète parce qu’il se centre sur les résultats or c’est l’interprétation qui compte.
Je trouve les « pseudos sciences » moins hypocrites, elles se posent en tant que croyance à adopter ou non. Les labels « démontré scientifiquement » est un argument purement marketing que l’on retrouve en science également dont je ne tiens pas compte ni pour les uns ni pour les autres.
Pour moi donc, on ne peut pas échapper à ces biais de raisonnement dans le domaine de la science qui sont de toute façon impossible à éradiquer faut arrêter de se leurrer, ils en font partie intégrante et il faut donc surtout apprendre à relativiser les résultats d’une recherche. Tout comme il faut apprendre à prendre ce qui nous ait utile dans la croyance et à rejeter ce qui ne nous convient pas. Chercher à éradiquer la croyance est selon moi peine perdue, elle est inhérente à l’esprit humain et il vaut mieux apprendre à s’en servir, ne pas lutter bêtement contre le courant mais savoir l’utiliser. »
Qu’en pensez-vous ?
Votre copain à l’air d’être un fan du post-modernisme. C’est populaire dans certains milieux intellectuels. Sa phrase «c’est la démarche (scientifique) qui est obsolète parce qu’il se centre sur les résultats or c’est l’interprétation qui compte. l’indique clairement.
Justement, l’idée de la méthode scientifique, c’est de minimiser le travail d’interprétation et de mettre le plus de distance possible entre les acteurs. C’est d’ailleurs pourquoi on travaille à double insu. En ce sens, votre copain fait l’apologie du biais de confirmation. L’autre chose qui choque bien de gens, c’est qu’en gros la méthode scientifique revient à dire que l’on ne peut penser pas soi-même. Même si c’est choquant, c’est la réalité. C’était d’ailleurs la conclusion de Kant dans critique de la raison pure.
Plus fondamentalement, il y a toujours de l’interprétation de la méthode scientifique et cela se fait toujours dans un contexte d’hypothèses auxiliaires. En épistmologie, cette situation est connus sous le nom de la thèse de Duhem-Quine. La différence entre la science et les pseudo-sciences, c’est qu’elles ne rejettent pas systématiquement des hypothèse qui ne font pas son affaire pour maintenir son marché.
Ok. Mais il y a des choses qu’il dit qui m’interpellent, par exemple :
« Par ailleurs parfois, quand un article de sciences sociales te dit que telle méthode ne marche pas alors que sur tes patients tu vois que si, qu’est-ce que tu peux te dire ? »
Est-ce un fait reconnu ou une croyance fausse ?
Le problème est de savoir ici, si son jugement est meilleur que ceux qui ont fait la recherche. Le domaine des sciences humaines souffre exactement des mêmes maux que le domaine biomédical dans ses pratiques. Les travaux sur la reproductibilité en psychologie, laissent aussi à désirer.
Ceci dit, j’ai tout de même l’impression que les mesures en situation contrôlées sont tout de même plus fiables que notre intuition personnelle qui est obtenue dans des situations encore moins contrôlées.
Voilà, je reviens un peu à la charge. J’ai continué le débat avec mon ami et il est arrivé à la conclusion suivante:
« L’article parle de rigueur au niveau des résultats et de la manière de les obtenir. […] Sa solution, dans l’article, est d’augmenter le seuil de significativité des résultats pour s’assurer de leur véracité. C’est comme si je te disais que par mesure de précaution, on ne reconnaît plus, que quelqu’un est à haut potentiel, que si il se trouve à 5 écart-types de la moyenne, et non plus à 2. C’est tout aussi arbitraire, c’est un seuil que l’on choisit d’instaurer. »
C’est curieux qu’il voit cela comme un seuil arbitraire, ce n’est pas du tout comme ça que je le perçois…
Le seuil est effectivement arbitraire. C’est toujours un compromis entre le nombre de faux positifs et le nombre de faux négatifs. Or, le problème actuel est qu’il y a objectivement beaucoup trop de faux positifs. La solution bête et méchante est alors de remonter le seuil.